首页 > 医疗资讯/ 正文
Alu元件是约300个碱基对的短散在元件(SINE),在整个人类基因组中分布超过100万个拷贝。虽然Alu元件在生物学和进化中的作用正在被探索,但部分Alu元件已被证明参与基因调控和结构变化。在癌细胞中,Alu元件可通过同源重组参与结构变化,在肿瘤进展期间低甲基化,并且该特征已被并入通过浆细胞游离DNA(cfDNA)分析的早期癌症检测方法。
理论上,全基因组测序(WGS)可以用于评估Alu元件,但开发相应的预测算法非常具有挑战性,这些挑战主要来自各元件彼此的相似性以及难以准确地鉴定。此前,美国约翰·霍普金斯大学医学院的科研团队开发了一种RealSeqS测序方法,可用于评估Alu元件的拷贝数变化。RealSeqS方法通过单个引物扩增约350,000个重复元件来评估cfDNA的非整倍性,提供了优于WGS的优势,包括更简单的工作流程,不需要构建文库,计算分析速度更快,单个Alu基因座的测序覆盖率更高等。
研究团队假设,对RealSeqS获得的大量测序数据进行公正的评估可能会揭示癌症患者和非癌症患者血浆样本之间的其他差异。这一假设通过一种名为A-PLUS的机器学习方法的开发进行了验证。研究团队利用在包括11种癌症类型的一系列病例对照样本集中开发并验证了该方法。在验证队列中,A-PLUS对11种不同癌症类型的敏感性为40.5%,特异性为98.5%。将A-PLUS与非整倍体和8种常见蛋白质生物标志物结合,检测出51%的癌症,特异性为98.9%。研究发现,A-PLUS的部分功效可以归因于一个单一的特征——实体癌患者cfDNA中Alu元件的整体减少。该成果已发表在Science Translational Medicine上,文章题为“Machine learning to detect the SINEs of cancer”。
虽然A-PLUS的性能还需要更多的验证研究来证实,但其敏感性和特异性与已有的Galleri检测等癌症筛查方法几乎相当。针对癌症的早期检测,研究团队相信A-PLUS能够成为比现有基于表观遗传学和片段组学检测方法更简单、更有效的新工具。

文章发表在Science Translational Medicine
主要研究内容
A-PLUS旨在检测cfDNA重复区域的差异,研究人员能够使用机器学习将其调整为正常和癌症相关信号的鉴别器。与其他从WGS中获得片段信号的方法不同,A-PLUS使用基于扩增子的方法,可以对基因组的目标区域进行更深层次的测序。
该团队在开发A-PLUS时纳入了几项原则:首先,试图识别和消除与技术噪音、种族、性别和批次差异相关的混杂位点;其次,使用主成分分析(PCA)缩小了特征数量;第三,使用了更多了样本量;第四,将样本分为四个预先指定且不重叠的队列,以最大限度地减少过度拟合。队列1用于选择特征并训练机器学习模型;队列2用于建立将样本评分为阳性或阴性的阈值;队列3用于独立测试或验证模型效果;队列4来评估评分系统的再现性。
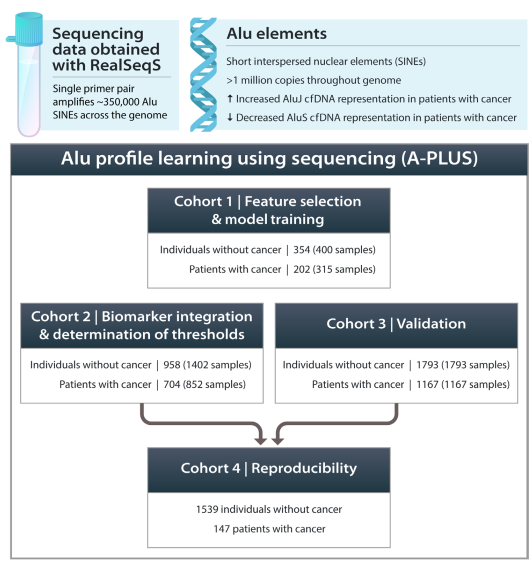
图1. 整体研究概述
队列1:
A-PLUS特征选择和模型训练
队列1由354名无癌个体和202名实体瘤患者组成。为了减少过拟合的可能性并在评价样本之前建立质量指标,研究人员使用先前发布的指标和阈值纳入患者,而不是因为与A-PLUS性能相关的任何指标而排除任何参与者。
训练的重要要素包括reads深度的标准化和去除覆盖不足的扩增子,以及去除基于T检验不稳定的扩增子数据。经过这些步骤,原来的350000个位点中有121197个保留下来。然后使用PCA降低维度,并使用支持向量机来识别前60个PCA特征。
队列2:
分析整合和阈值测定
队列2包括来自704名实体瘤患者和958名非癌对照个体的样本。在血液采集时没有转移,并且与队列1一样,癌症包括来自食道、胃、乳腺、结直肠、肺、卵巢和胰腺的癌症。在队列2中,对应于对照样本中99%特异性的A- PLUS评分为0.28,在该阈值下,来自患有食道癌和胃癌患者的样本具有最高的灵敏度。
研究团队还在队列2中生成了全局非整倍体评分(GAS)。GAS使用不同的机器学习方法来生成反映39个染色体臂的获得或丢失的单个评分。GAS阈值大于0.64在队列2的对照样本中产生99%特异性。在99%特异性下,食管癌和肝癌的灵敏度最高(43% CI:26-62%和37% CI:17-61%),乳腺癌的灵敏度最低(6% CI:4-10%)。在GAS测定评分为阴性的687个癌症样本中,318个在A-PLUS测定中评分为阳性;相反,81%在GAS中得分为阳性的癌症样本在A-PLUS中得分也为阳性。此外,A-PLUS阳性非癌样本在GAS中得分为阳性的现象没有出现。
然后,研究团队使用逻辑回归将A-PLUS和GAS与蛋白质生物标志物整合到多个分类器中,使用10倍交叉验证评估性能,发现阈值大于0.87产生99%特异性。食管癌和肝癌患者的敏感性最高,乳腺癌患者的敏感性最低。
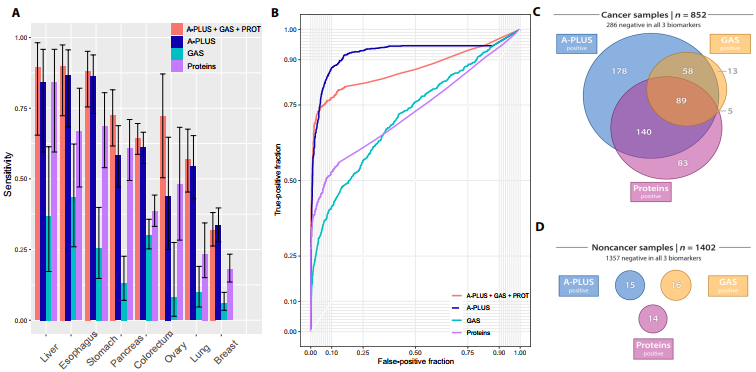
图2. 队列2血浆样品中的癌症检测
队列3:
独立验证
队列3样本来自2960例个体,包括1167例患有11种类型实体瘤的患者:乳腺癌、结直肠癌、食管癌、头颈部癌、肾癌、肺癌、卵巢癌、胰腺癌、前列腺癌、胃癌和子宫癌。
研究团队使用队列2定义的99%阈值评估队列3中所选测定方法的性能。对于A-PLUS,在队列3中观察到的特异性(98.5%)略低于队列2预期的99%。在队列2和队列3中评估的七种癌症类型中,癌症类型敏感性相似。在队列2和3中,单独非整倍体以及单独蛋白质生物标志物的灵敏度和特异性也相似。结合A-PLUS、非整倍性和蛋白质方法以98.9%的特异性能够检测到以下器官中的癌症:食道癌、胰腺癌、卵巢癌、胃癌和结直肠癌。
研究团队随后进行了比较分析,发现与非整倍体或蛋白质生物标志物相比,A-PLUS对阳性检测的贡献更大,A-PLUS可检测到41%的非整倍体或蛋白质未检测到的样品。
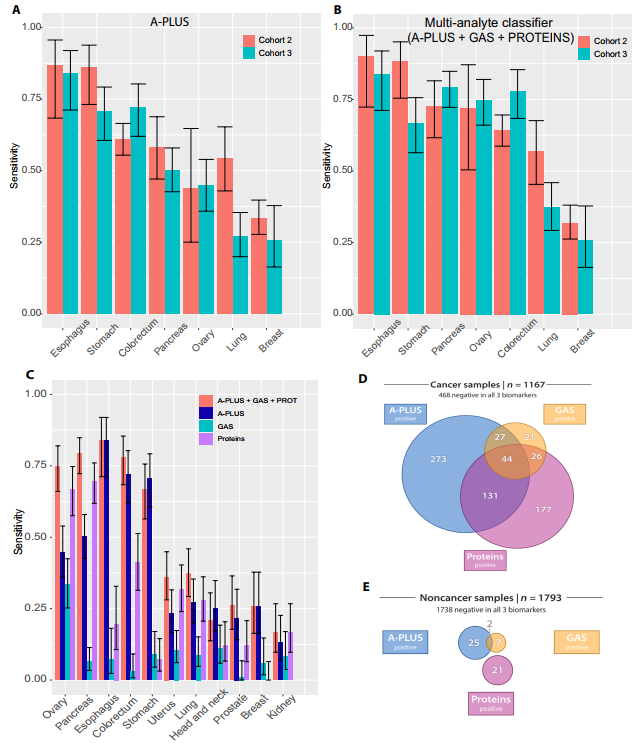
图3. 队列3血浆样品中的癌症检测
队列4:
再现性
最后,研究团队在来自队列2或队列3的1686名个体中评估了A-PLUS和GAS测定(均基于RealSeqS测序数据)的技术再现性。所有样本均为在同一时间点从同一患者采集的技术重复样本。
使用队列2定义的阈值,1632对中有95.8%的评分一致(阳性或阴性),A-PLUS的Cohen kappa为0.56。A-PLUS的不完全一致性反映了特异性和灵敏度之间的平衡。有目的地将特异性设置为非常高(99%),这可能会限制灵敏度。因此,在相同的预设阈值下,重复检测的特异性之间的差异仅为1.2%,而重复检测的灵敏度之间的差异超过10倍。
对于GAS,99.3%的配对是一致的,其中Cohen kappa为0.66。与队列3相比,队列4中GAS的敏感性较低,这是由于队列4中的大多数癌症病例来自乳腺癌患者,而队列3中只有6%的癌症来自乳腺癌,在队列3中,乳腺癌的GAS最低。

图4. 在技术重复中的再现性
结 语
对SINE的代表性元件Alu的评估可以增加非整倍性检测癌症的能力。在RealSeqS数据中,在设定的特异性下,A-PLUS算法相对于单独的非整倍体所实现的灵敏度显著增强。研究团队将来自癌症患者和无癌对照的样本预先指定为四个组群,用于模型训练、分析整合以及阈值确定、验证和再现性。在验证队列中,Alu元件的评估具有提高几种用于早期癌症检测方法性能的潜力。
文章共同第一作者Kamel Lahouel表示:“自从完成了当前文章中描述的工作以来,希望之城团队已经创建了一个新版本的A-PLUS,用来检测癌症和对照组之间片段长度差异的信号。”据悉,基于该方法已经开展了一项前瞻性临床试验,旨在衡量其在65-75岁成年人中检测癌症的有效性。
论文原文:
Douville C, Lahouel K, Kuo A, Grant H, et,. Machine learning to detect the SINEs of cancer. Sci Transl Med. 2024. doi: 10.1126/scitranslmed.adi3883.
https://www.science.org/doi/10.1126/scitranslmed.adi3883
- 搜索
-
- 1000℃Nutrients:真实世界数据,纤维肌痛患者的饮食与运动自适应规律
- 1000℃D-二聚体升高诊治与管理专家共识(2026)
- 1000℃专家论坛|文良志:门静脉血栓的诊断和治疗
- 1000℃首例儿童NF2驱动型胸膜间皮瘤,多方法学检测锁定NF2双等位基因失活和14/22号染色体缺失,提示与成人胸膜间皮瘤不同
- 1000℃打破误区:干扰素追求CHB功能性治愈,HBsAg为何“不降反增”?
- 1000℃迷惑性极强的肝内病灶!影像表现疑点重重,最终病理竟查出两种不同肝脏恶性肿瘤
- 1000℃指南共识|原发性肝癌分子靶向药物相关蛋白尿中西医结合诊疗专家共识
- 1000℃Diabetologia:意大利北部社区 1~100 岁人群胰岛自身抗体与乳糜泻 TGA-IgA 的年龄分布及检测方法学验证
- 精J Child Psychol Psychiatry:12种罕见神经发育障碍儿童沟通能力谱系
- 精研究发现:爱吃辣的人,心血管病和癌症死亡风险都会显著降低
- 精Nursing in Critical Care:别再指责护士了!ICU 里被遗漏的护理,根源在系统而非个人
- 精Acta Obstet Gynecol Scand:罕见病女性的妊娠并发症与母婴结局,一项单中心434种罕见病的回顾性队列研究
- 精【爱儿小醉】儿科患者术前对流层臭氧暴露与围手术期呼吸系统不良事件之间的关系:一项单中心回顾性队列研究
- 精eBioMedicine:牙龈下微生物组与脑健康存在连续关联梯度,牙周炎或成认知衰退可干预靶点
- 精军事医学研究院《自然·通讯》:自适应IrPtCu纳米酶水凝胶实现耐药菌感染伤口序贯治疗
- 精能够逆转萎缩性胃炎的两个中成药,该怎么选择?
- 荐同时性多发性原发性肺癌,左右病灶分别为EGFR和ALK阳性,考虑淋巴结肿大仅局限左肺门及血浆EGFR阳性,采用奥希替尼联合化疗
- 荐40岁女性同时罹患卵巢支持细胞-间质细胞瘤和透明细胞乳头状肾肿瘤,WES等基因检测竟为阴性
- 荐椎管内麻醉使用止血药突发气道痉挛的抢救流程解析
- 荐女子肝区无任何不适,影像提示复杂囊性病变,层层鉴别后锁定罕见胆管源性囊性肿瘤
- 荐“绘”真报告 | 病理考虑为中枢神经细胞瘤,检出脑室外神经细胞瘤的特征性变异FGFR1-TACC1融合,辅助鉴别诊断
- 荐8岁女童出现男性化症状,竟是形似「性索-间质肿瘤」的卵巢「无性细胞瘤」所致,少见KRAS/CDK4共扩增或与侵袭性有关
- 荐17例病例分析揭示常见于中年人的色素性室管膜瘤临床特征与预后,分子检测可助力临床精准诊疗
- 荐Lancet Oncol:结直肠癌腹膜转移,围手术期化疗并非必选项
- 标签列表
-
- 星座 (702)
- 孩子 (526)
- 恋爱 (505)
- 婴儿车 (390)
- 宝宝 (328)
- 狮子座 (313)
- 金牛座 (313)
- 摩羯座 (302)
- 白羊座 (301)
- 天蝎座 (294)
- 巨蟹座 (289)
- 双子座 (289)
- 处女座 (285)
- 天秤座 (276)
- 双鱼座 (268)
- 婴儿 (265)
- 水瓶座 (260)
- 射手座 (239)
- 不完美妈妈 (173)
- 跳槽那些事儿 (168)
- baby (140)
- 女婴 (132)
- 生肖 (129)
- 女儿 (129)
- 民警 (127)
- 狮子 (105)
- NBA (101)
- 家长 (97)
- 怀孕 (95)
- 儿童 (93)
- 交警 (89)
- 孕妇 (77)
- 儿子 (75)
- Angelababy (74)
- 父母 (74)
- 幼儿园 (73)
- 医院 (69)
- 童车 (66)
- 女子 (60)
- 郑州 (58)